详细说明distinct 与 row_number()与over() 的区别
1 前言
在咱们编写 SQL 语句操作数据库中的数据的时候,有可能会遇到一些不太爽的问题,例如对于同一字段拥有相同名称的记录,我们只需要显示一条,但实际上数据库中可能含有多条拥有相同名称的记录,从而在检索的时候,显示多条记录,这就有违咱们的初衷啦!因此,为了避免这种情况的发生,咱们就需要进行“去重”处理啦,那么何为“去重”呢?说白了,就是对同一字段让拥有相同内容的记录只显示一条记录。
那么,如何实现“去重”的功能呢?对此,咱们有两种方式可以实现该功能。
第一种,在编写 select 语句的时候,添加 distinct 关键词;
第二种,在编写 select 语句的时候,调用 row_number() over() 函数。
以上两种方式都可以实现“去重”功能,那两者之间有何异同呢?接下来,作者将给出详细的说明。
2 distinct
在 SQL 中,关键字 distinct 用于返回唯一不同的值。其语法格式为:
SELECT DISTINCT 列名称 FROM 表名称
假设有一个表“CESHIDEMO”,包含两个字段,分别 NAME 和 AGE,具体格式如下:
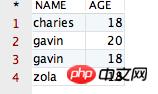
观察以上的表,咱们会发现:拥有相同 NAME 的记录有两条,拥有相同 AGE 的记录有三条。如果咱们运行下面这条 SQL 语句,
/** * 其中 PPPRDER 为 Schema 的名字,即表 CESHIDEMO 在 PPPRDER 中 */ select name from PPPRDER.CESHIDEMO
将会得到如下结果:
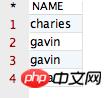
观察该结果,咱们会发现在以上的四条记录中,包含两条 NAME 值相同的记录,即第 2 条记录和第 3 条记录的值都为“gavin”。那么,如果咱们想让拥有相同 NAME 的记录只显示一条该如何实现呢?这时,就需要用到 distinct 关键字啦!接下来,运行如下 SQL 语句,
select distinct name from PPPRDER.CESHIDEMO
将会得到如下结果:
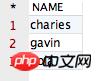
观察该结果,显然咱们的要求得到实现啦!但是,咱们不禁会想到,如果将 distinct 关键字同时作用在两个字段上将会产生什么效果呢?既然想到了,咱们就试试呗,运行如下 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
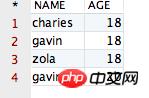
观察该结果,哎呀,貌似没有作用啊?她将全部的记录都显示出来了啊!其中 NAME 值相同的记录有两条,AGE 值相同的记录有三条,完全没有变化啊!但事实上,结果就应该是这样的。因为当 distinct 作用在多个字段的时候,她只会将所有字段值都相同的记录“去重”掉,显然咱们“可怜”的四条记录并不满足该条件,因此 distinct 会认为上面四条记录并不相同。空口无凭,接下来,咱们再向表“CESHIDEMO”中添加一条完全相同的记录,验证一下即可。添加一条记录后的表如下所示:
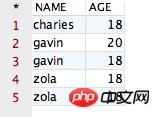
再运行如下的 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
观察该结果,完美的验证了咱们上面的结论。
此外,有一点需要大家特别注意,即:关键字 distinct 只能放在 SQL 语句中所有字段的最前面才能起作用,如果放错位置,SQL 不会报错,但也不会起到任何效果。
3 row_number() over()
在 SQL Server 数据库中,为咱们提供了一个函数 row_number() 用于给数据库表中的记录进行标号,在使用的时候,其后还跟着一个函数 over(),而函数 over() 的作用是将表中的记录进行分组和排序。两者使用的语法为:
ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
意为:将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序
接下来,咱们还用表“CESHIDEMO”中的数据进行测试。首先,给出没有使用 row_number() over() 函数时查询的结果,如下所示:
然后,运行如下 SQL 语句,
select PPPRDER.CESHIDEMO.*, row_number() over(partition by age order by name desc) from PPPRDER.CESHIDEMO
得到的结果如下所示:
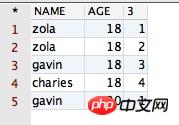
从上面的结果可以看出,其在原表的基础上,多了一列标有数字排序的列。那么反过来分析咱们运行的 SQL 语句,发现其确实按字段 AGE 的值进行分组了,也按字段 NAME 的值进行排序啦!因此,函数的功能得到了验证。
接下来,咱们就研究如何用 row_number() over() 函数实现“去重”的功能。通过观察上面的结果,咱们可以发现,如果以 NAME 分组,以 AGE 排序,然后再取每组的第一个记录或许就可以实现“去重”的功能啊!那么试试看,运行如下 SQL 语句,
/* * 其中 rn 表示最后添加的那一列 */ select * from (select PPPRDER.CESHIDEMO.*, row_number() over(partition by name order by age desc) rn from PPPRDER.CESHIDEMO) where rn = 1
运行后,得到的结果如下所示:
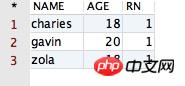
观察以上的结果,我们发现,哎呀,数据“去重”的功能一不小心就被咱们实现了啊!不过很遗憾,如果咱们细心的话,会发现一个很不爽的事情,那就是在执行以上 SQL 语句进行“去重”的时候,有一条 NAME 值为“gavin”、AGE 值为“18”的记录被过滤掉了,但是在现实生活会中,同名不同年龄的事情太正常了。
4 总结
通过阅读及实践以上内容,咱们已经知道了,无论是用关键字 distinct 还是用函数 row_number() over() 都可以实现数据“去重”的功能。但是在实现使用的过程中,咱们要特别注意两者的用法特点以及区别。
在使用关键字 distinct 的时候,咱们要知道其作用于单个字段和多个字段的时候是有区别的,作用于单个字段时,其“去重”的是表中所有该字段值重复的数据;作用于多个字段的时候,其“去重”的表中所有字段(即 distinct 具体作用的多个字段)值都相同的数据。
在使用函数 row_number() over() 的时候,其是按先分组排序后,再取出每组的第一条记录来进行“去重”的(在本篇博文中如此)。当然,在此处咱们还可以通过不同的限制条件来进行“去重”,具体如何实现,就需要大家自己去动脑思考啦!
最后,在本篇博文中,作者详述了自己对用关键字 distinct 和函数 row_number() over() 进行数据“去重”的一些认识,希望以上的内容能够对大家有所帮助!
【相关推荐】
1. Mysql免费视频教程
2. 详解innodb_index_stats导入数据时 提示表主键冲突的错误
3. 实例详解 mysql中innodb_autoinc_lock_mode
以上就是详解distinct 和 row_number()和over() 的区别的详细内容,更多请关注php中文网其它相关文章!
……