LABB-CAT电脑端官方正版2024最新版绿色免费下载安装
软件介绍
LABB-CAT是一款基于浏览器的语言学研究工具,它可以存储录音和正则表达式的可搜索的访谈文字记录,搜索结果、整个笔录和媒体,可以以各种格式查看或导出。
功能介绍
媒体和记录本的存储
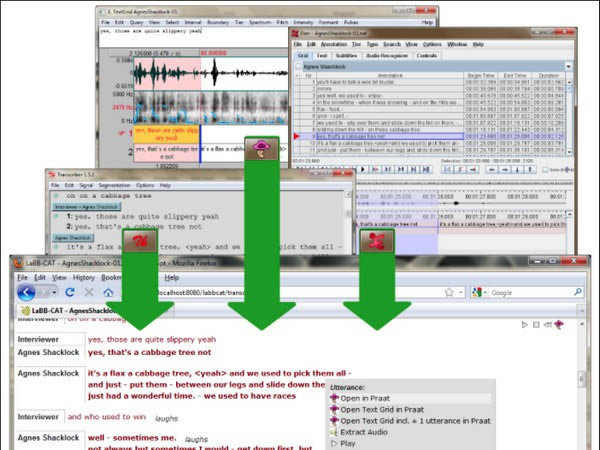
LaBB-CAT本质上是一个音频/视频记录的时间对齐誊本的存储库。 可使用Transcriber、Praat或ELAN(可用于创建一个文件,将誊本文本与音频/视频记录中的相应位置对齐)制作时间对齐的誊本。然后,誊本被上传到LaBB-CAT,它允许存储有关发言人和誊本的附加信息。
来自Transcriber、Praat或ELAN的誊本。
征求意见的任务
您还可以定义诱导任务,包括提示参与者阅读和问题,让他们回答。
当参与者完成任务时(使用他们的浏览器或移动设备),他们的语音会被记录下来并自动直接上传到LaBB-CAT。
自动注释
结合信号数据、原始正字转写本以及一些第三方数据和工具,可以对转写本进行自动标注,例如。
词汇标签
来自CELEX的注释借助CELEX的数据,可以用更多的数据自动注释单词。
语音学
教学大纲
形态学
语气
频率
其他词典也可以整合,包括CMU发音词典和Unisyn词典。
强制对齐
在HTK或WebMAUS的帮助下,在语句层面对齐的抄本可以强制对齐到词和段层面。
用HTK强制对齐
统计层
LaBB-CAT数据库本身的词频数据可以直接对每个词进行计算和标注。
词频层
语言学探究和字数"(LIWC)可以用来比较语料库和参考语料库。
LIWC比较
结合CELEX的时间排列信息和音节数,可以计算出不同领域的语音率。
每分钟的音节数,行和转弯的音节数
斯坦福解析器
在Stanford Parser的帮助下,可以为转录本生成可编辑的句法树。
跨越句法成分的注释。
解析树表示法
脚本
脚本可以用Python或Javascript编写,以执行arbtrary计算和注释任务。
用于计算对偶变异性指数的Python脚本
IBM Watson人格洞察力
LaBB-CAT可以与IBM Watson的Personality Insights网络服务集成,对抄本进行人格分析。
手动注释
注释可以手动添加,比如说。
主题标签
针对单个单词的文本标签
时间点或区间可以使用Praat进行注释。
使用Praat对点进行标注
检索
一旦记录本和注释到位,就可以对符合特定标准的记录本进行搜索(例如,基于发言者的年龄/性别、记录本所属的语料库等)。
按属性过滤发言者
当发言者被选中后,可以在不同的层中搜索他们的语句,以寻找文本或常规表达。
在 "成人 "话题中搜索 "the",然后在音素层搜索以I、E、i或@开头的单词。
这将返回与查询相匹配的所选抄本中所有语句的列表。
搜索结果
如果需要,可以将此列表连同相关的演讲者和注释信息直接导出到csv文件,以便在Excel或R中进行进一步分析。
搜索结果
或者可以提取音频样本进行分析。
从结果中提取音频
或者可以直接使用EMU-webApp编辑语句注释和对齐。
使用EMU-webApp编辑手机对齐。
如果语句已被强制对齐,可以用Praat对目标语段进行批量处理。
用Praat进行批量处理,以提取形体和其他声学措施。
批量Praat处理可以包括您自己的自定义Praat脚本。
自定义Praat脚本,用于搜索结果的批量处理。
另外,点击搜索返回的语句,就会产生有关发言者的完整文字记录,与相关语句一起置于屏幕顶部。可以点击誊本的任何部分,并播放媒体的相应部分。
交互式文字稿
直接从交互式转录页面播放媒体,显示其他注释层,提取该行的音频,或在 Praat 中打开包含注释的相应 TextGrid。可以添加、编辑或删除注释,并调整对齐方式。
……
LABB-CAT电脑端官方正版2024最新版绿色免费下载安装 >>本地高速下载
>>本地下载
